Cooperative Open Access eXchange (COAX)
(This is the second of two posts forming my contribution to Open Access Week 2015.)
The following proposal was written as a thought-experiment to test, in a recognisable problem-space, the idea outlined in my previous post, The Active Repository Pattern. I was able to call on the the advice of colleagues at EDINA who have world-class expertise in the area of 'routing' open-access metadata and content.
The United Kingdom Council of Research Repositories (UKCoRR) was invited to comment, and many members of that organisation provided some very valuable feedback, for which I am very grateful! It is fair to say that this idea has generated a degree of interest from that community.
This is the first public airing of the proposal, with the UKCoRR feedback incorporated.
Cooperative Open Access eXchange (COAX) - a proposal
Elevator pitch
According to estimation by colleagues at EDINA, based on data gathered by the Repository Junction Broker (also formerly known as the Jisc Publications Router), the mean average number of authors for a scholarly article is 6.3. This means that, when the corresponding author does the right thing and deposits the manuscript in their local institutional repository there are, on average and potentially, 5 other repositories which might be interested in getting a copy of that manuscript. What if institutional repositories could participate in a cooperative mechanism, sharing manuscripts between them according to need?
The primary ‘user-story’
As a repository manager I would like to receive, or at least be notified of, a paper deposited in another institutional repository where that paper has one or more authors affiliated to my institution, so that I can more easily acquire papers of relevance to my repository (and in so doing satisfy my funder's requirements)
Basic assumptions
- A journal article is often written by more than one author, from more than one institution: that should be the default use case for repositories.
- The author(s)’ accepted manuscript (AAM) is held by the publisher and by the corresponding-author. It may also be held by another of the listed authors.
- Any one of the listed authors may deposit the AAM in their respective institutional repository.
- There are internationally-accepted standard identifiers for many of the objects and parties within the field of scholarly communication, such as DOI, ISSN, ISNI (ORCID) etc. Although these are not always present in the metadata, it is desirable that they should be.
- The primary user-story is best served by an ‘event-driven’ approach, where repositories send immediate notification that they have had a new paper deposited into them, rather than by a periodic ‘harvesting’ approach, where some system enquires of all repositories about recent deposits.
- Wide-spread use of a single, well-defined metadata application profile will mitigate some aspects of this problem space. For example, RIOXX, which is in the process of being implemented across UK institutional repositories, and which is gaining interest beyond the UK, and OpenAIRE which is already established in parts of Europe.
Working principles and constraints
- This document is concerned with a narrow, focussed problem-space. This is essentially defined in the primary user-story, above. Reference is made to aspects of this which have wider relevance or application, but these are not explored in detail here.
- The document attempts to articulate and design the Simplest Solution that could Possibly Work (outlined later in The Minimum Viable Product section). The approach leans towards a light-weight solution, with minimal centralised infrastructure.
- Initially, other related solutions, projects or initiatives are ignored until the problem and a possible, logical approach to solving it, have been clearly articulated.
Terminology and component parts
The following actors, assets and events appear in the use-cases described below - although not all in every use-case. The bold, short name in square brackets is the label used in the descriptions and diagrams for each use-case.
- institutional repository, which may be one of:
- the repository which already has the paper [Origin IR]
- the repository which may be interested in receiving notification about and (perhaps) a copy of the paper [Target IR]
- institutional repository manager [IRM]
- manuscript, usually a PDF [MS]
- metadata record describing the MS [Record]
- system for handling ‘notifications’ to/from repositories [Hub]
- system for matching manuscripts to appropriate repositories [Matcher]
- database of institutional repositories with contact details [IR DB]
- database of metadata records with contact details [Record DB]
- a text-mining function for extracting metadata from manuscripts [Text-miner]
More detailed descriptions of some of these components can be found in a later section.
The Minimum Viable Product (use-case 1)
Use-case 1 describes the the ‘Minimum Viable Product’ (MVP) which can support the primary user-story.
This MVP establishes some components and data-flows. These not only set the ground for a minimal system which can begin to satisfy the primary user-story, but also provide the foundations for future development and improvement.
Description
When an Origin IR has an MS (together with some metadata) deposited [1] into it, the Origin IR automatically notifies [2] the Hub, sending it the metadata Record and the MS. The Hub calls [3] the Matcher, which invokes [4] the Text-miner which mines the MS for extra metadata. The Matcher then enhances the Record and stores [5] it in the Record DB before identifying which (if any) IRM(s) to notify. The Matcher then instructs [6] the Hub to send [7] an email notification, containing the Record, to the IRM(s) it believes might be interested in that Record.
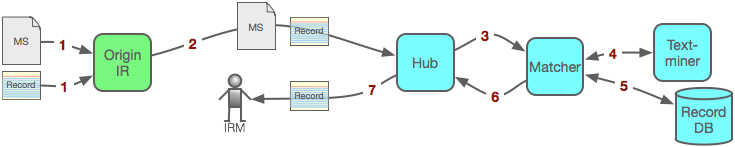
Notes
- the Matcher references the Record DB which records what has been sent and where, so that it knows not to send the same Record more than once to a given IRM
- the MS itself is not transmitted, but the Record should contain the URL from which it can be directly downloaded by the interested IRM
- the MS is not kept or made available to Target IRs under any circumstances.
Challenges
The primary challenge to be overcome is in deciding which Target IRs might be interested in a given MS. There is more than one possible approach to ascertaining this, and the COAX strategy is to employ several such approaches, including:
- assertion in metadata records coming from Origin IRs, where other institutions are directly referenced
- text-mining manuscripts for references to institutions
- finding indirect associations with institutions through author affiliations
- exploiting ORCIDs
- extrapolation based on comparing records in bulk (e.g. these authors often write together)
This use-case depends upon the possibility of extracting some usable metadata from the manuscript itself. However, there is no substantial extra work or cost for the Origin IR to despatch the manuscript along with the metadata record, so we include this in the MVP.
It is hoped that widespread adoption of ORCIDs may create opportunities for matching authors to institutions (and hence repositories). However, it is not yet certain that the use of ORCIDs will become ubiquitous (not to say reliable) and, in any case, it will be some time before such levels of mainstream use can be achieved. Moreover, as the ORCID system matures, it will bring with it a growing issue of ‘false positives’ in this use-case, as each author’s number of affiliated institutions becomes potentially larger.
Another significant challenge is to avoid sending unnecessary notifications to Target IRs. If a manuscript is deposited in more than one participating Origin IR, then it would be beneficial if the system could recognise that it has already received information and sent notification about this manuscript, and avoid sending notification again. Such matching will be inexact, since most metadata records associated with a deposited AAM do not, at the time of deposit, contain a global identifier (typically a DOI). However, there may be strategies which can be used to match records to an acceptable level of accuracy without such global identifiers in place.
Other use-cases
These other use-cases are offered for comparison.
Use-case 2: simple, email notification triggered by initial deposit with manuscript as attachment
This use-case builds on use-case 1, with an additional step of fetching the MS from the originating IR and adding it to the email as an attachment for convenience.
Description
When an Origin IR has an MS (together with some metadata) deposited [1] into it, the Origin IR automatically notifies [2] the Hub, sending it the metadata Record and the MS. The Hub calls [3] the Matcher, which invokes [4] the Text-miner which mines the MS for extra metadata. The Matcher then enhances the Record and stores [5] it in the Record DB before identifying which (if any) IRM(s) to notify. The Matcher then instructs [6] the Hub to send [7] an email notification, containing the Record and the MS (as email attachment), to those IRM(s) it believes might be interested in that Record.
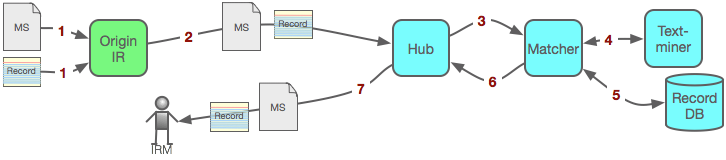
Notes on use-case 2
- builds on use-case 1, with an additional step of fetching and sending the manuscript.
Challenges
AAMs are not always simple PDF - they can be in various formats, and be comprised of multiple files. Furthermore, AAMs may be under embargo and therefore not openly available on the Web. This means that the automated retrieval of AAMs is a significant challenge. Use-case 1 avoids this problem by relying on repository managers to fetch the AAM manually (requesting it by email if necessary).
Manuscripts held in repositories may be under embargo. The system would need to take account of this such that it did not disseminate the manuscript to other repositories in violation of any embargo agreement with the publisher. The MVP (use-case 1) avoids this issue by never disseminating the manuscript to Target IRs.
Use case 3: automated fetch and deposit of manuscript and metadata
Description
When an Origin IR has an MS (together with some metadata) deposited [1] into it,, the Origin IR automatically notifies [2] the Hub, sending it the metadata Record and the MS. The Hub calls [3] the Matcher, which invokes [4] the Text-miner which mines the MS for extra metadata. The Matcher then enhances the Record and stores [5] it in the Record DB before identifying which (if any) IRM(s) to notify. The Matcher then instructs [6] the Hub to deposit [7] into the Target IR(s) a SWORD package, containing the Record and the MS.
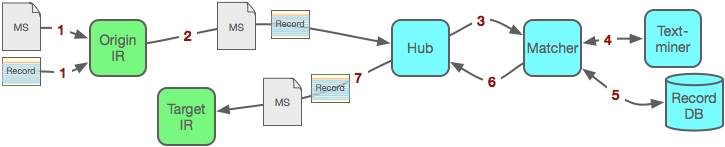
Notes on use-case 3
- this use-case introduces a more sophisticated level of machine-to-machine interoperability, where the Target IR is able and willing to accept metadata and content deposited directly into it from a trusted source, without requiring the immediate intervention by the IRM
Challenges
(as in use-case 2)
Descriptions of some of the main components
Matcher
The Matcher is a service which:
- matches different metadata records (coming from different repositories) describing the same resource
- extracts authors from metadata records and identifies their repository affiliations
The matcher operates with approximations of a ‘match’, observing pre-defined thresholds of ‘confidence’ before instructing the Hub to send notifications.
Hub
The Hub is envisaged as an industry-standard message handling system, capable of receiving ‘messages’ from registered systems and relaying these, asynchronously, to other registered systems or processes according to a defined set of rules.
Next steps
I hope that this has been sufficient to stimulate some thinking about how an Active Repository Pattern might allow us to accelerate open-access to all publicly-funded research. Please do comment below!